智谱GLM-5.2开源登顶:开源模型首次追平Claude Opus,全球AI格局重塑
📖 名词释义
AI Box(又称 AI盒子 / 智能体计算机 / Agent Computer),是一种专门运行 AI Agent 的本地硬件设备,预装智能体应用管理系统,开箱即用,7×24 小时在线运行。用户可以通过微信、飞书、企业微信、钉钉等社交软件远程指挥 AI 帮你干活。
摘要:6月17日智谱AI正式开源GLM-5.2,753B参数的MoE大模型,在Artificial Analysis综合榜单以51分登顶所有开源权重模型,在Code Arena百万用户盲测中取得全球可用模型第一。在FrontierSWE长程任务测试中仅比Claude Opus 4.8低1%,首次代表开源力量逼近闭源前沿。MIT开源协议,可自由商用。
6月17日,智谱AI发布并开源了新一代旗舰大模型GLM-5.2。
这件事在AI圈引发了不少讨论。不是因为它是"又一个国产大模型"——而是因为它创造了一个历史节点:开源模型第一次在全球权威评测中,逼近了Claude Opus 4.8这个级别的闭源顶级选手。
它到底强在哪
编程能力登顶全球可用模型第一。 Code Arena是一个由超百万用户参与的真实盲测平台——不是机构自己做题,是真实用户在真实任务中打分。GLM-5.2在这个盲测中取得全球可用模型第一,超越了Claude Opus 4.7、GPT-5.5等所有可用的闭源模型。
前端开发榜单排名第二,仅次于已下线的Claude Fable 5——注意是"所有可用模型中"排名第二,意味着它是目前普通用户能调用到的、最强的前端编程模型。
长程任务逼近Claude Opus 4.8。 FrontieSWE是专门测试"AI能不能像软件工程师一样,在数小时尺度上完成复杂技术项目"的基准。GLM-5.2得分74.4%,比Claude Opus 4.8低1%,比GPT-5.5高1%,比Claude Opus 4.7高出11%。
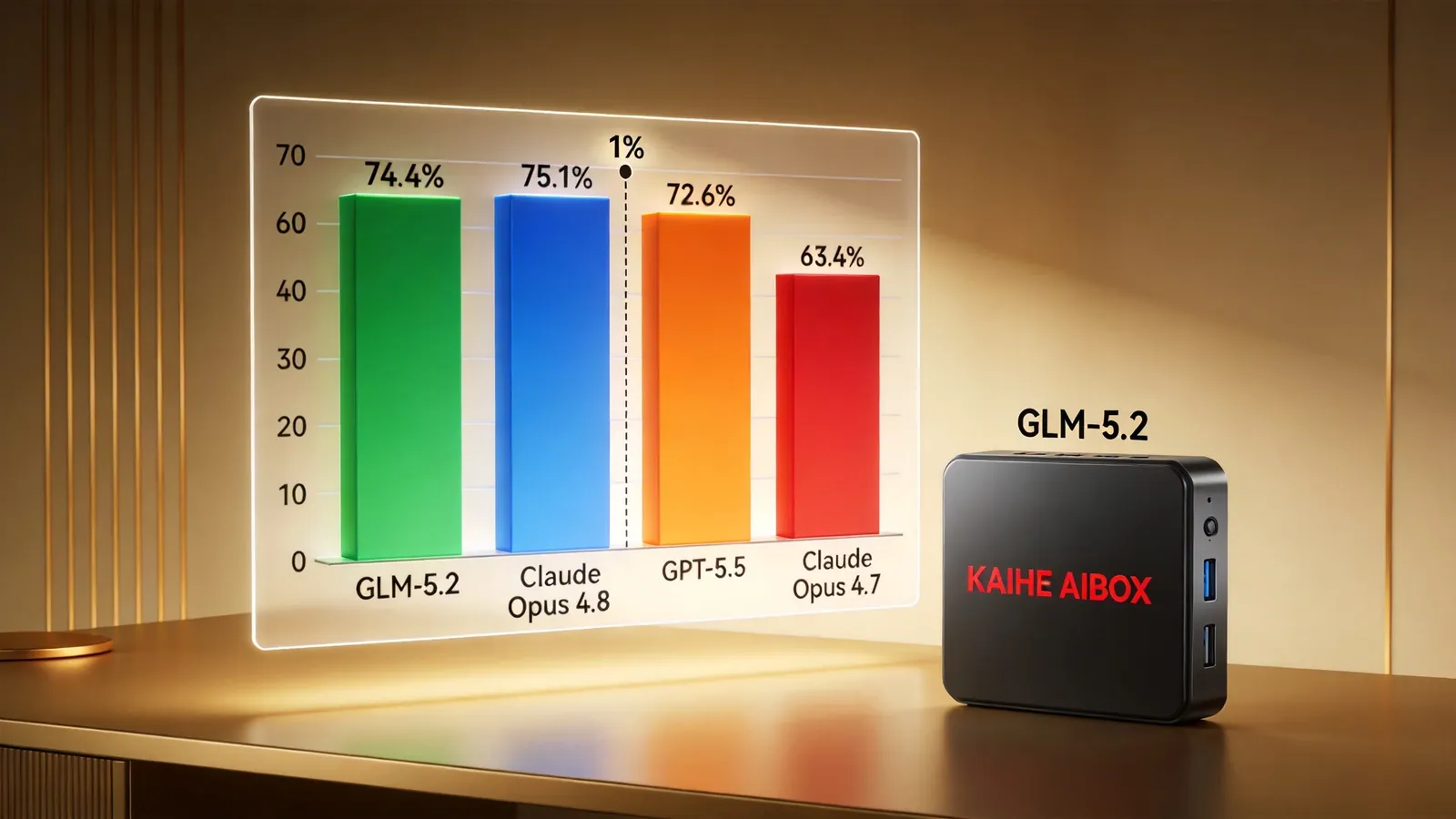
翻译成人话:在需要"持续干活几小时不跑偏"的任务上,GLM-5.2和地表最强的Claude Opus 4.8基本持平,大幅领先其他所有模型。
1M上下文不是噱头。 市面上声称支持100万上下文的模型不少,但超过一定长度后就开始"失忆"——前边的信息记不住。GLM-5.2的1M上下文是经过专项强化训练的,在88万token的真实输入测试中仍能稳定工作,没有出现性能衰减。
综合榜单登顶意味着什么
Artificial Analysis发布的Intelligence Index v4.1综合榜单上,GLM-5.2以51分登顶所有开源权重模型,大幅领先MiniMax-M3(44分)、DeepSeek V4 Pro(44分)和Kimi K2.6(43分)。
这个榜单不是单一维度——综合了编程、推理、数学、多模态等多个方向的能力评分。GLM-5.2能在这个综合榜上登顶,说明它不是"只会编程"的偏科生,而是在各个方向都有竞争力的全面选手。
榜单也反映了全球AI格局的一个变化:由Anthropic、OpenAI、智谱等顶尖模型厂商形成的"新御三家"格局正在形成。
MIT开源意味着什么
GLM-5.2采用MIT开源协议——这是最宽松的开源许可之一,意味着:你可以免费使用、可以商用、可以修改、可以分发,不需要向智谱付费或申请授权。
模型已经上传至Hugging Face(zai-org/GLM-5.2),支持vLLM和SGLang本地部署。如果你有足够的GPU算力,可以把整个模型部署在自己的服务器上,不依赖任何API。

这对企业用户很有吸引力——数据不用上云,模型跑在自己机器上,成本是一次性算力投入而不是持续的API调用费用。
价格:API定价8元/百万输入
GLM-5.2的API定价是8元/百万输入tokens。这个价格在国产旗舰模型中属于中等偏上——比DeepSeek贵,但能力也明显更强。
对于普通开发者来说,如果日常任务是编程、长程任务、多文档分析,GLM-5.2的能力提升值得这个差价。对于高频调用的大企业用户,也可以考虑开源部署自己做推理优化。
对铠盒AIBOX用户的价值
GLM-5.2的开源对铠盒AIBOX用户来说是一个好消息。
之前A1用户可选的国产强模型主要是DeepSeek——性能不错,价格便宜,但长程任务和编程能力相比GLM-5.2有差距。
现在A1的管理后台可以配置GLM-5.2的API——在模型配置页面选择智谱,输入API Key,就能用上这个全球最强的开源编程模型。
具体适合场景: - 编程任务:代码生成、调试、代码审查——GLM-5.2的编程能力是目前最强开源模型 - 长文档分析:合同、报告、论文——1M上下文能完整处理一本书的体量 - 长程Agent任务:需要持续工作数小时的任务——GLM-5.2的长程任务能力比DeepSeek更强
理性看待
"开源模型追平Claude Opus"这个说法有冲击力,但需要补充几个前提:
盲测≠所有任务。 Code Arena和Design Arena的盲测反映的是前端开发这个特定场景的能力。在其他场景(写作、多模态、数学推理),GLM-5.2和Claude Opus 4.8的差距可能更大。
开源≠免费。 MIT开源的是模型权重和架构,但实际运行需要GPU算力。一张H100的租金每小时几美元,部署753B参数的模型需要多卡并行——这不是普通开发者能轻易承担的成本。API调用才是普通用户的主流用法。
能力提升是真实的。 不管怎么说,GLM-5.2在编程和长程任务这两个最难的方向上,确实达到了接近顶级的水平。这是开源模型第一次做到这件事,意义是真实的。
想了解更多内容,可以点击进入主页。
延伸
相关文章《铠盒AIBOX A1跑DeepSeek实测:千元内性价比最高的国产AI方案》—— 另一个国产模型实测 相关文章《一台设备接所有大模型:铠盒AIBOX支持GPT/Claude/DeepSeek/豆包自由切换》—— 多模型对比
-#智谱GLM-5.2 #开源大模型 #铠盒AIBOX #AI前沿 #国产AI
铠盒AIBOX | 让AI 7×24小时替你干活的智能体计算机 · AI前沿